
はじめに
みなさん、こんにちは。自動化大好きまっきーです。今回は前回ご紹介した実践チャレンジ、#66DaysOfDataの第1章Day1 ~ Day7についてご紹介して見たいと思います。
設問を理解し、自分の力でやって見てください!詰まったら回答を軽く見て、また戻ってを繰り返すといいと思います。
初級編 をクリアした人は、クリアできるはずです!
では始めましょう!
今回のテーマ ~#66DaysOfData Import Data~
そもそも#66DaysOfDataってなに?という方はこちら。
覚えてほしいこと
データソースのカラムの意味について理解する
データ読み込みで文字化けするときはEncodingに注目
Challenge 1 - Import Data
まずは初めなので難易度低めです。このセクションを通して達成すべき内容はざっと下記の通りです。
Day1 - データセットのダウンロード
下記のリンク(Kaggleへ移動)から、それぞれ下記の3つのファイルをダウンロードします。
また、それぞれのカラムの意味も理解しておきましょう。
Day2 - KNIMEとは? を理解する
下記を読みましょう。
Day3 - KNIMEをインストールする・KNIME Hubのアカウントを作る
下記を読みましょう。
Day4 - 新しいworkflowを作成する
- LOCALの下に、新規フォルダ(Workflow group)と新規workflowを作ります。名前は任意です。
- 作ったフォルダの下に、"Data"というフォルダを新しく作ります。
- 最後に作ったDataのフォルダ下にダウンロードしたcsvファイルを移動させます。
- Refreshボタンを押すと、KNIME Explorer 上から
下記を読みましょう。
Day5 - tracks.csvを取り込む
tracks.csvを読み込む。
データを取り込むのに使用するNodeは下記の3つのいずれかから選択します。
- File Reader
- File Reader (Complex)
- CSV Reader
KNIME Explorerからworkflow上にDrag&dropをするとどのNodeで設定されるかを確認して見ましょう。
注意:“Limit data rows scanned”のオプションを調整して正しくデータ型を推定させる必要があるかもしれません。
取り込んだら、Table Viewを開いてOutputを確認します。この時、全てのRowが正しく読み込まれているかどうか確認して見てください。
注意:多くの曲名はASCIIというエンコーディングになっていない場合があります。どのエンコーディングが正しいか、Optionで調整してください。
いづれのNodeでどのNodeがどの程度フレキシブルに調整できるのか、読み込みスピードに違いがあるのかなどをチェックして見ましょう。
下記を読みましょう。
Day6 - 相対パスを使用してcsvファイルを取り込む
相対パスの概念を理解し、tracks.csvを相対パスで取り込みましょう。
下記を読みましょう。
Day7 - 注釈をつける
Nodeの名前を変更したり、workflowに注釈をつけて、このプロジェクトについてのタイトル・説明を記載してください。
下記を読みましょう。
まっきーの解答
データのダウンロード
ダウンロードしたzipファイルを展開して、KNIME workspaceの下にフォルダを作って置いています。
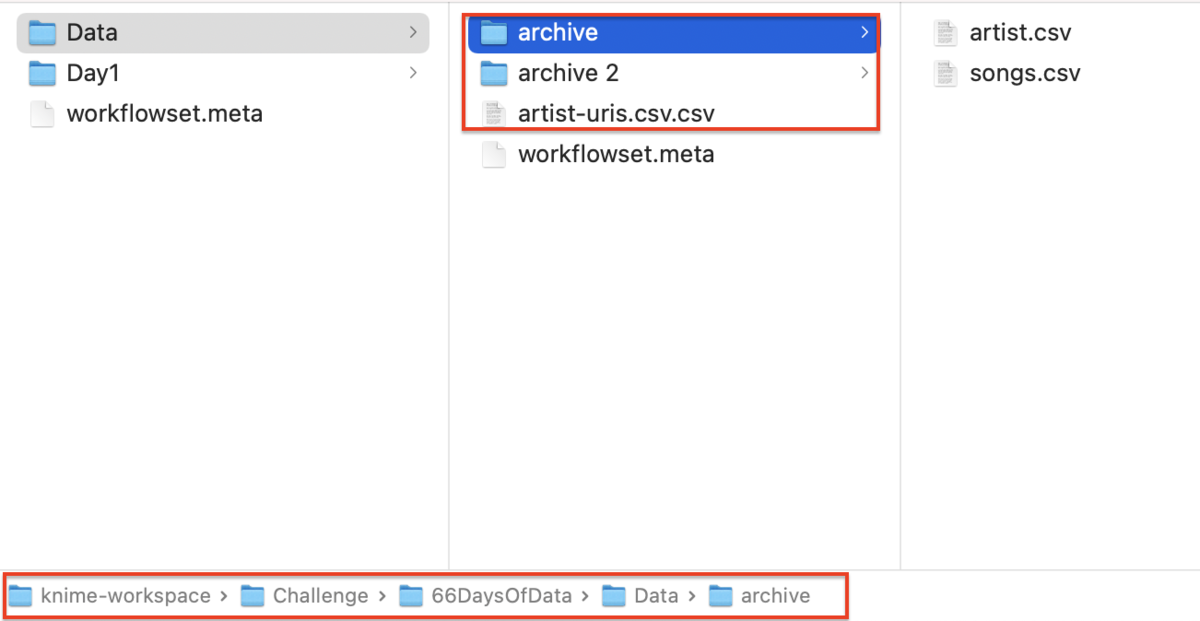
workflowの作成
workflowを新規に作成します。
ちなみにダウンロードしたファイルは下記のように見えています。

データの読み込み・コメントの作成
今回はFile Readerを使用しました。パスは相対パスを使用しています。
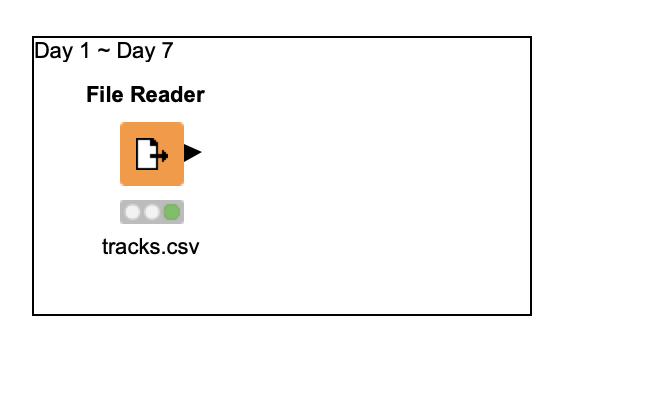
読み込んだら、データが正しく読まれているか確認しておきましょう。

ちょっと一言
データソースのカラムの説明
参考:#66DaysOfData Resources Datasets | KNIME
今後データ分析の課題が出てくると、元データにどんなデータが入っているのかを理解するのはとても重要です。あとから見直せるようにどんなデータなのか先に押さえておきましょう。
tracks.csv - 曲名リスト
1900年 ~ 2021年までのおよそ600,000 件の曲情報が格納されているデータ。20カラムある。
- id - 曲の固有ID (track unique ID)
- name - 曲名 (track name)
- duration_ms - 曲の長さ[milliseconds]
- explicit - 歌詞に暴力的な単語・放送禁止用語・露骨な表現等が含まれている楽曲かどうか。(1 が含まれている。0が含まれていない)
- artists - アーティスト名 (artist name)
- id_artists - アーティスト固有ID (リスト型表記 collection)
- release_date - リリース日
- danceability - ダンスに向いている度 (0~1 : 1が一番ダンスに向いている)
- energy - 曲の激しさ (0~1 : 1が激しい) 例えば、ヘビーメタルのような楽曲が1、バッハのような曲が0
- key - 曲のキー(調)(0 = C, 1 = C♯/D♭, 2 = D など) 音楽で習う用語で言うとハ長調とか。
- loudness - 音の大きさ、音圧のレベル
- mode - その曲の調性を表す。メジャーを1、マイナーを0として表記
- speechiness - スピーチ度という曲中の話し言葉度合いを数値化したもの。(0が少なく、1が多い。) オーディオブック、トークショー、詩の朗読のような曲だと1に近づくイメージ。
- acousticness - アコースティック度 (0~1) 1に近づくとアコースティック感が強い
- instrumentalness - 楽器度(0~1) ボーカルが入っている度。0が全く歌っていないオーケストラのような曲。OhhとかAhhは楽器として扱われる。ラップなどはボーカルとして扱われる。
- liveness - ライブ度。(0~1) 観衆の声が入っているようなライブ感が曲の中にあれば1に近づく。レコーディングスタジオで収録されたような曲は0
- valence - 曲を通して伝わってくるポジティブ度。(0~1) 1に近づくにつれポジティブ(楽しい・陽気・幸福感)
- tempo - テンポ。曲全体のBPM (beats per minute)
- time_signature - 拍子記号(メーター)1小節に何拍子あるか
The artist-uris.csv - アーティストリスト
カラムヘッダはないが、アーティスト名が81000行ほど入っており、IDと名前が含まれる。(これの信憑性はわからない。)
- [id_artists] artist unique ID
- [artists] artist name
artist.csv - アーティストリスト
tracks.csv とかなり似ているデータセットだが、アーティストの人気度が含まれている
- popularity - アーティストの人気度 (0~100) 100が一番人気
おわりに
継続は力なり、ぜひみなさんやって見てください!
Spotfiyは同じようなデータをAPIで公開しているみたいなので、音楽好きな方は一度APIを叩いて分析してみても面白いかもしれないですね。
ではまた!
KNIME Hubワークスペース
Twitter アカウント
まっきー | デジタル推進課 (@makkynm) | Twitter
KNIMEに関する本
KNIMEに関する日本語の本って今これくらいしかないと思うんですよね、、
本がいいなーと言う人はぜひ試してみてください。
