
誰向きの記事か?
この記事はこんな方に向いています。
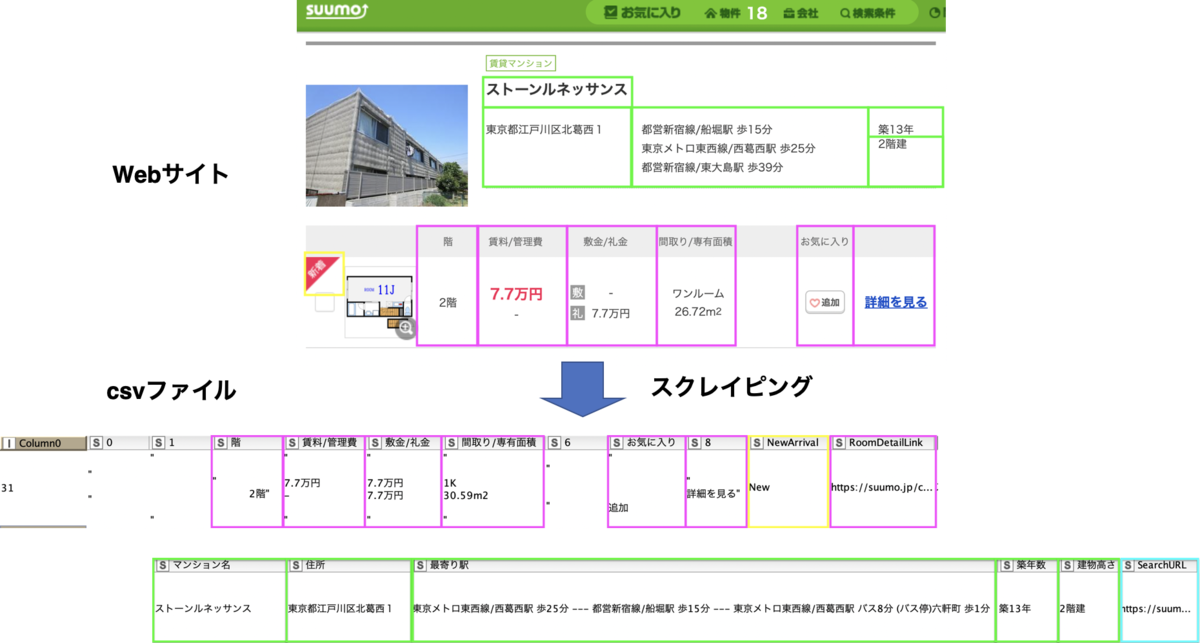
SUUMOから物件情報を抽出して
はじめに
こんにちは、自動化大好きまっきーです。普段は自動化ツールKNIMEについて解説しています。諸事情あり、現在東京のお得物件を探し回っています。でもSUUMOやその他のサイトのUIって個人的にもう少し足りないんです。。
特に下記の機能ですね。是非実装して欲しいです。
- 目的駅までの徒歩+電車の所要時間、運賃でフィルタリング(例: 東京駅まで徒歩+電車で60分以内の物件を洗い出す)
- 地図上から家賃を色表示、フィルタリング
- 周辺平均坪単価より安い
- 東京都内だけでなく、関東圏内でフィルタリングを効かせたい
賃貸を探すときどうせならお得な物件に住みたいですよね。そしてそれを効率的に探したいです。不動産の物件データベースにアクセスできればいいんですが、不動産業者でもない私がアクセスできるわけがありません。
なので1週間くらい頑張りました。今回は第一歩となる、SUUMOのスクレイピングについて解説したいと思います。
今回のテーマ ~SUUMOの物件データ~
今回のテーマ ~SUUMOの物件データ~
覚えてほしいこと
SUUMOスクレイピングは個人利用目的のみOK。
やりたいこと
東京から比較的近い、関東の一人暮らしお得物件を見つける!
必須条件
条件:管理費・共益費込み 12万円以下 15分以内 15年以内 2階以上/室内洗濯機置場/バス・トイレ別 / 鉄筋系/鉄骨系/ブロック・その他/ 東京都
任意条件
- 東京駅までの徒歩+電車の所要時間が60分以内
- 物件が相場よりも安くお得
- 川や海の近く
目的達成までのステップ
- SUUMOをスクレイピングして物件情報収集
- 前処理をして必要情報を取得
- 解析にかけてお得物件を洗い出す
今回はその第一ステップとして、SUUMOをスクレイピングして、東京都内の物件データを集めてきます。
ソースファイル
ソースファイルはこちらからダウンロードできます。
Inputファイルはありません。本来であればcsvファイルなどをInputファイルにすべきなんですが、面倒でやめました。
BaseURLsの部分を変更すれば使えると思います。Jupyter Notebookのファイルはデバッグで使った部分も残っているので少し汚いです。。
github.com
一応、全コードを一番下につけておきました。
実行方法と出力フォーマット
実行までのステップ
Macでも、Windowsでも問題ありません。Pythonが実行できる環境を用意してください。ここら辺は一般的なPythonのお話なのでスキップします。モジュールも、特に変なものは使っておらず、ごくごく一般的なものです。
- Python3をインストールする
- 必要モジュールをインストールする(BeautifulSoup / requests / pandas / time / urljoin)
- ソースファイル上のBaseURLsを編集:SUUMOのURLのルール(詳細は後ほど)に基づき、重複のない大きな括りのURLを入力します。例えば、東京都の全物件一覧の1ページ目と神奈川県の全物件一覧の1ページ目とかですね。
- ソースファイルを実行する
実行時の動き
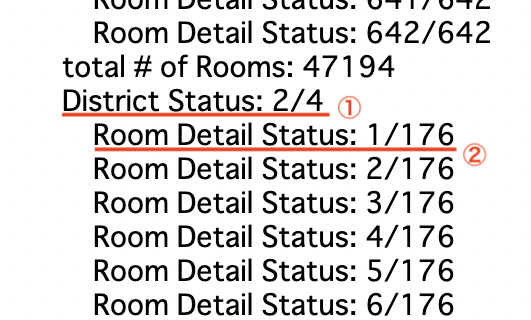
実行時、大きく2つの進捗状況が確認できます。
- District Status:BaseURLsに基づく総数と現在の状況。BaseURLsのリストに4つ入力すると、1/4から始まり、4/4で終わります。
- Room Detail Status:BaseURLsから検索されるページの総数と現在の状況。例えばBaseURLsが東京都全体で最大のページ数が640だとすると、1/640 ~ 640/640まで続きます。
現在5秒の待機処理がそれぞれのステップで入っています。サーバーに負荷のかからない十分に長い秒数を設定しましょう。この待機時間と合計URL数でおよその終了時間が予測できますね。
実行時の動き
出力フォーマット
出力はBaseURLsごとにされます。結果は部屋ごとに、csvで出力されます。
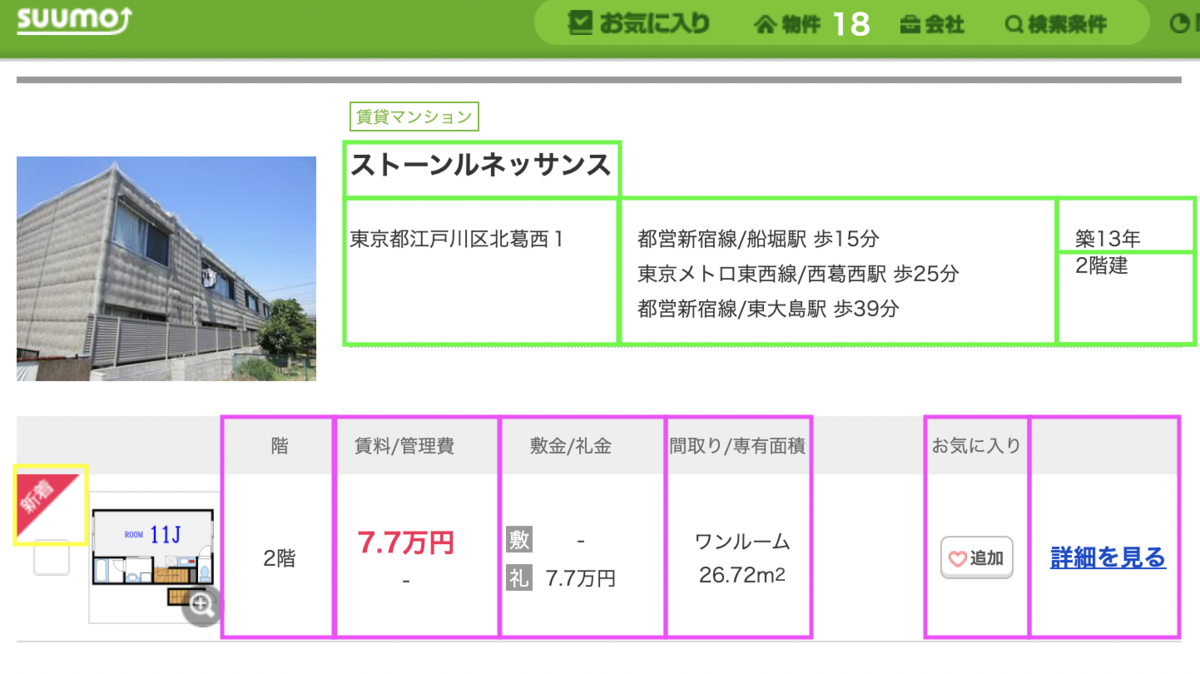
元物件データ
CSVファイルのデータはちょっとExcelで見ずらかったので、KNIMEを使って見せています。1行は部屋単位です。セルの結合とかはしていないので、複数部屋が空いている場合は、住所などの情報は重複した表示になります。

出力CSVデータ

出力CSVデータ続き
これらのデータは、もちろん前処理にかける必要があります。こちらの前処理については、KNIMEを使って次回解説してみようと思います。
全体ワークフロー
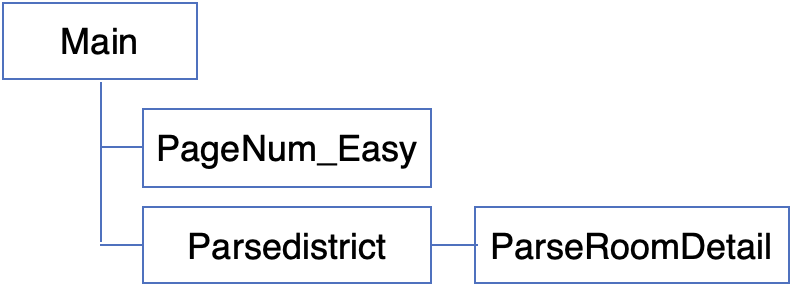
下記のようにプログラムが実行されます。
プログラムの構造
ラフですが、大まかなフローチャートは下記の通りです。
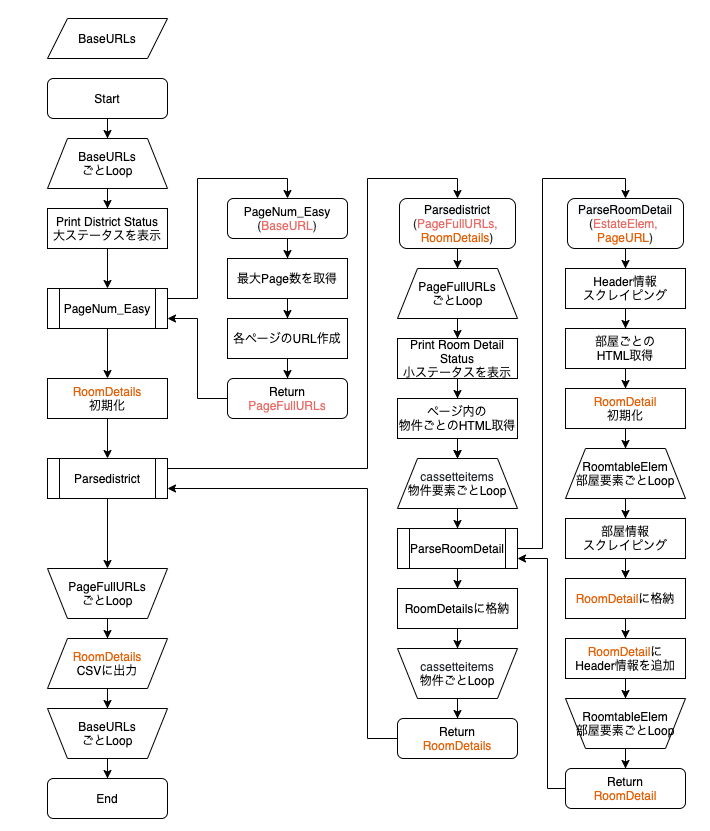
全体ワークフロー フローチャート
各関数の役割
これらの関数は私が作ったものなので、全然無視していただいていいです。ただ意味が分かってた方が改修しやすいですよね。
- PageNum_Easy:最大ページ数を取得して、全ページ数のURLを作成する関数です。BaseURLを引数として、全ページのURLのリストを返します。SUUMOのページ数の表示が「&page=」になっていることを前提にこの関数が使えます。
- Parsedistrict:ページ内に表示されている建物の要素をリストで取得します。建物ごとにParseRoomDetailを呼び出します。返ってきた結果はRoomDetailsに格納します。
- ParseRoomDetail:建物1つの要素を引数として持ち、建物の空き部屋情報を取得して返します。
- Recursive_PageNum:使っていません。全ページのURLを再帰関数で取得するものです。時間がかかる上に、サーバーに負荷がかかるので使わなくていいと思います。
各モジュールの役割
from bs4 import BeautifulSoup
import requests
import pandas as pd
import time
from urllib.parse import urljoin
- BeautifulSoup:ウェブスクレイピングメインモジュール。htmlの構造解析用
- requests:htmlを取得するため
- pandas:csvで出力するため
- time:sleepを入れてサーバーへの負荷を減らすため
- urljoin:相対URLを絶対URLに変換するため
検索元URLリスト - BaseURLs
まずInputファイルに当たる部分です。本来Inputファイルで読むべきですが、今回は面倒だったので直接入力しました。
ここでは、検索元URLを指定します。SUUMOでは、検索条件がURLに現れてきます。
BaseURLs = [
"https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=13",
"https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=14",
"https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=12",
"https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=11"
]
SUUMOのURLの構造
SUUMOのURLの構造について詳しくみていきます。
例えば、
条件:12万円以下 15分以内 15年以内 2階以上/室内洗濯機置場/バス・トイレ別 管理費・共益費込み 鉄筋系/鉄骨系/ブロック・その他/ 東京都
の場合のURLは
https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=13
となります。
条件を一つ一つ変えると理解できるのですが、代表的なURLの意味は、
- cb=0.0 : 0万円以上
- ct=12.0 : 12万円以下
- et=15 : 15分以内
- cn=15:築15年以内
- ta=13 :東京都(都道府県コード13)
というような感じです。
このほか区や市単位になると、エリアコードが出てきます。例えば東京23区はsc=13101 ~ 13123で表されます。
今回は、都道府県ごとに結果を出したいので、ta=の部分のみを変えたURLを入れておきます。それぞれの都道府県コードは下記の通りです。
- ta=11:埼玉県
- ta=12:千葉県
- ta=13:東京都
- ta=14:神奈川県
メインプログラム - BaseURLsごとスクレイピング実行・出力
メインプログラムになります。BaseURLsごとに処理をしています。途中関数を2回呼び出して、最終的にそれらの結果をpandasを使用してcsvファイルで出力しています。
for iMcount, url in enumerate(BaseURLs):
print("District Status: " + str(iMcount + 1) + "/" + str(len(BaseURLs)))
All_PageFullURLs = []
All_PageFullURLs = PageNum_Easy(url)
RoomDetails = []
RoomDetails = Parsedistrict(All_PageFullURLs, RoomDetails)
df = pd.DataFrame(RoomDetails, columns = HeaderNames)
filename = "SUMMO_FullRoom_" + str(iMcount) + ".csv"
df.to_csv(filename)
大枠ステータスの表示
まず、Printの部分でBaseURLsごとのステータスを出力しています。これにより、大枠の進捗状況が確認できます。今回で言うと、都道府県レベルでどれが終わったのかが分かりますね。
print("District Status: " + str(iMcount + 1) + "/" + str(len(BaseURLs)))
全ページのURL取得 - PageNum_Easy関数の呼び出し
次に、PageNum_Easy関数を呼び出して、全ページのURLを取得しています。返り値は全URLのListになっています。
All_PageFullURLs = PageNum_Easy(url)
スクレイピング結果の取得 - Parsedistrict関数の呼び出し
次に、取得した前URLをスクレイピング実行関数"Parsedistrict"に引き渡します。返り値は、スクレイピング結果になっています。
RoomDetails = Parsedistrict(All_PageFullURLs, RoomDetails)
スクレイピング結果の出力 - pandas data frameにしてcsv出力
最後に取得した全データをListからPandasのDatafameに変換して、csv出力していきます。出力はBaseURLsごとに行われます。
df = pd.DataFrame(RoomDetails, columns = HeaderNames)
filename = "SUMMO_FullRoom_" + str(iMcount) + ".csv"
df.to_csv(filename)
この時のHeaderNamesは下記のように、Main Programの前で取得しています。これは、どのページも部屋の情報が入っているテーブルの形は同じであるという前提で、BaseURLsの最初のページを代表値としてヘッダ情報を取得しています。
また、建物に紐づく情報などは、手入力で追加しています。
soup = BeautifulSoup(requests.get(BaseURLs[0]).content, "html.parser")
body = soup.find("body")
RoomtableHeadElem = body.find("div",{'class':'cassetteitem'}).find("thead").find_all("th")
HeaderNames = [temp.get_text() for temp in RoomtableHeadElem]
HeaderNames.append("NewArrival")
HeaderNames.append("RoomDetailLink")
HeaderNames.extend(["マンション名", "住所", "最寄り駅", "築年数", "建物高さ","SearchURL"])
HeaderNames = [temp.replace("\xa0", str(i)) for i, temp in enumerate(HeaderNames)]
全ページURL取得関数 - PageNum_Easy関数
具体的に、各関数の中身について解説します。この関数は、SUUMOのページ数の表示が「&page=」になっていることを前提に作られています。
def PageNum_Easy(url):
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c, "html.parser")
body = soup.find("body")
pages = body.find("div",{'class':'pagination pagination_set-nav'})
links = pages.select("a[href]")
nPages = [int(link.get_text()) for link in links if link.get_text().isdigit()]
if len(nPages) == 0:
PageFullURLs = [url]
else:
MaxPages = sorted(nPages)[-1]
PageFullURLs = []
for ipg in range(MaxPages):
base_URL = url + '&page=' + str(ipg+1)
PageFullURLs.append(base_URL)
return PageFullURLs
Step1 - ページ数のHTML部抜き出し
- BaseURLのHTMLを取得し、ページ数の部分を抜き出します。この時、リンクが有効のもののみを抜き出すので、1ページ目は抜き出されません。
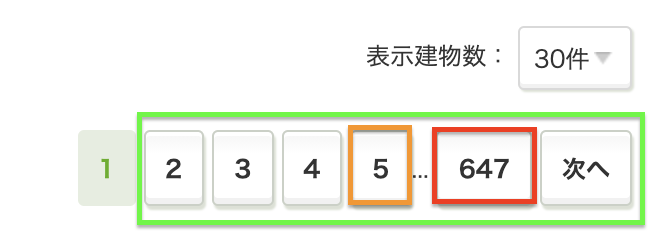
全ページURL取得
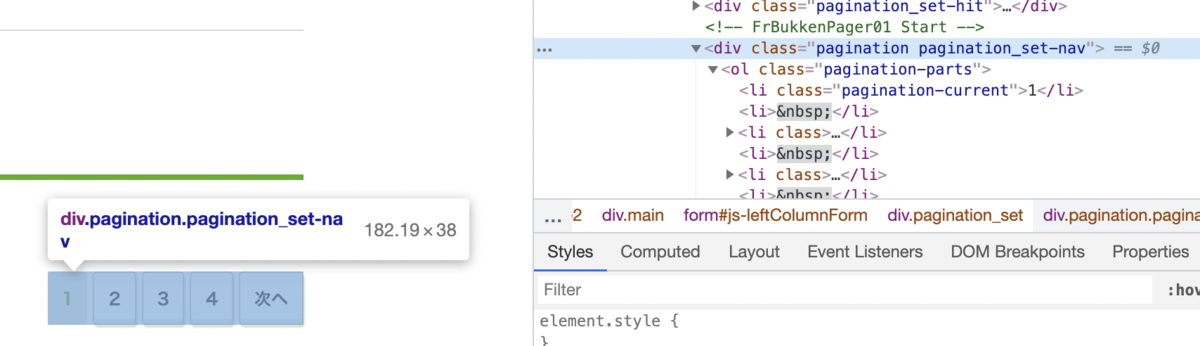
全ページURL取得
Step2 - ページ数を数値に変換
「次へ」のリンクは邪魔なので、数値に変換できるもののみをリストに格納します。ここでのnPagesはページ数の数値のリストになります。
nPages = [int(link.get_text()) for link in links if link.get_text().isdigit()]
Step3 - 最大ページ数を取得
リスト内の最大値を取得すれば、最大ページ数が得られます。ここで注意点として、1ページしかなかった場合空リストになるので、if文で条件分けしています。最大数が分かったら、あとはURLを「&page=」の規則で作るだけです。
if len(nPages) == 0:
PageFullURLs = [url]
else:
MaxPages = sorted(nPages)[-1]
PageFullURLs = []
for ipg in range(MaxPages):
base_URL = url + '&page=' + str(ipg+1)
PageFullURLs.append(base_URL)
物件要素取得関数 - Parsedistrict関数
全ページURLリストを引数として、スクレイピング結果を返す関数です。建物ごとの実際のスクレイピングは次の関数ParseRoomDetailが担当しています。
ページごとにループを回しています。
def Parsedistrict(PageFullURLs, RoomDetails):
for icount, url in enumerate(PageFullURLs):
print(" Room Detail Status: " + str(icount + 1) + "/" + str(len(PageFullURLs)))
try:
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c, "html.parser")
summary = soup.find("div",{'id':'js-bukkenList'})
cassetteitems = summary.find_all("div",{'class':'cassetteitem'})
for EstateElem in cassetteitems:
RoomDetails.extend(ParseRoomDetail(EstateElem, url))
except requests.exceptions.RequestException as e:
print("エラー : ",e)
time.sleep(5)
print("total # of Rooms: " + str(len(RoomDetails)))
return RoomDetails
Step1 - 建物ごとのHTML要素を取得
まずは建物の要素を取得します。cassetteitemsに、建物ごとの要素がリストで格納されています。SUUMOではデフォルトで最大30件の表示なので、このリストの大きさは30です。
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c, "html.parser")
summary = soup.find("div",{'id':'js-bukkenList'})
cassetteitems = summary.find_all("div",{'class':'cassetteitem'})
Step2 - スクレイピング結果を出力用リストに格納
次に、建物ごとでループを回してParseRoomDetail関数を呼び出します。ParseRoomDetail関数は、その建物の全部屋のスクレイピング結果をリストで返してくれるので、.extend()を使用して出力用リスト、RoomDetailsに格納していきます。
for EstateElem in cassetteitems:
RoomDetails.extend(ParseRoomDetail(EstateElem, url))
建物・部屋情報スクレイピング関数 - ParseRoomDetail関数
建物ごとにスクレイピングを実行する関数です。建物のHTML要素を引数として、部屋ごとのスクレイピング結果をリストで返します。
def ParseRoomDetail(EstateElem, url):
EstateName = EstateElem.find("div",{'class':'cassetteitem_content-title'}).get_text()
EstateAddress = EstateElem.find("li",{'class':'cassetteitem_detail-col1'}).get_text()
EstateLocationElem = EstateElem.find("li",{'class':'cassetteitem_detail-col2'}).find_all("div",{'class':'cassetteitem_detail-text'})
EstateLocations = [EstateLocation.get_text() for EstateLocation in EstateLocationElem]
EstateLocation = ' --- '.join(EstateLocations)
EstateCol3Elem = EstateElem.find("li",{'class':'cassetteitem_detail-col3'}).find_all("div")
EstageAge = EstateCol3Elem[0].get_text()
EstageHight = EstateCol3Elem[1].get_text()
HeaderInfo = [EstateName, EstateAddress, EstateLocation, EstageAge, EstageHight, url]
RoomtableElem = EstateElem.find("table",{'class':'cassetteitem_other'})
RoomDetail = []
for rooms in RoomtableElem.find_all("tbody"):
Roomtable = [temp.get_text() for temp in rooms.findAll('td')]
if "cassetteitem_other-checkbox--newarrival" in rooms.td['class']:
Roomtable.append("New")
else:
Roomtable.append("Exsiting")
Roomlinks = EstateElem.select("a[href]")
RoomDetailURL = [link.get("href") for link in Roomlinks if link.get_text() == "詳細を見る"][0]
RoomFullDetailURL = urljoin("https://suumo.jp/", RoomDetailURL)
Roomtable.append(RoomFullDetailURL)
Roomtable.extend(HeaderInfo)
RoomDetail.append(Roomtable)
return RoomDetail
Step1 - 建物単位の情報をスクレイピング
まず、建物単位の情報を抜き出してHeaderInfoにリストで格納します。マンション名や最寄り駅などですね。
マンション名
マンション名は{'class':'cassetteitem_content-title'}です。
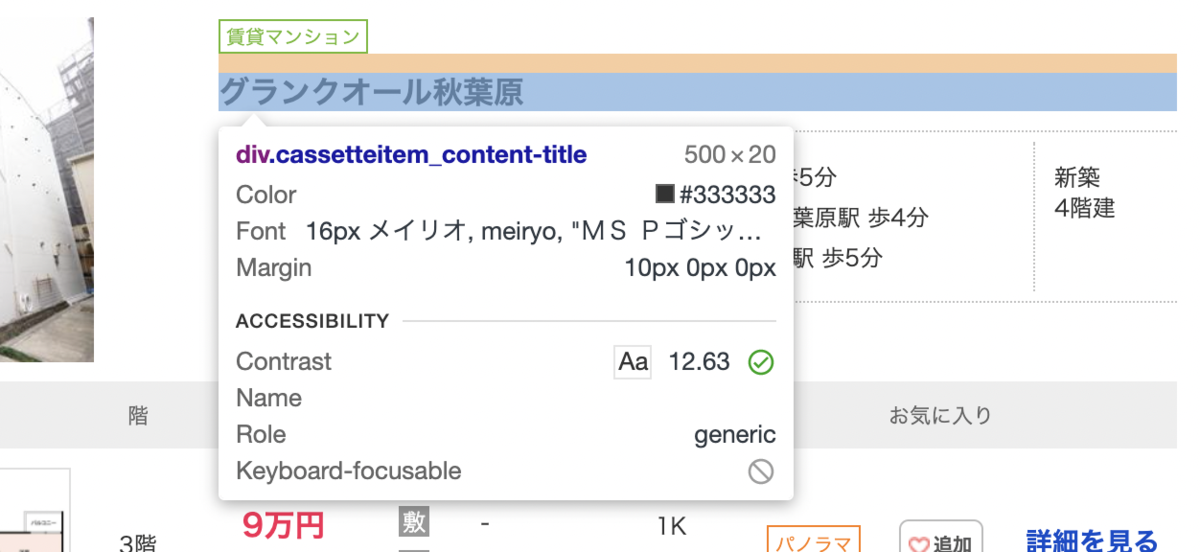
建物単位のスクレイピング - マンション名
EstateName = EstateElem.find("div",{'class':'cassetteitem_content-title'}).get_text()
住所
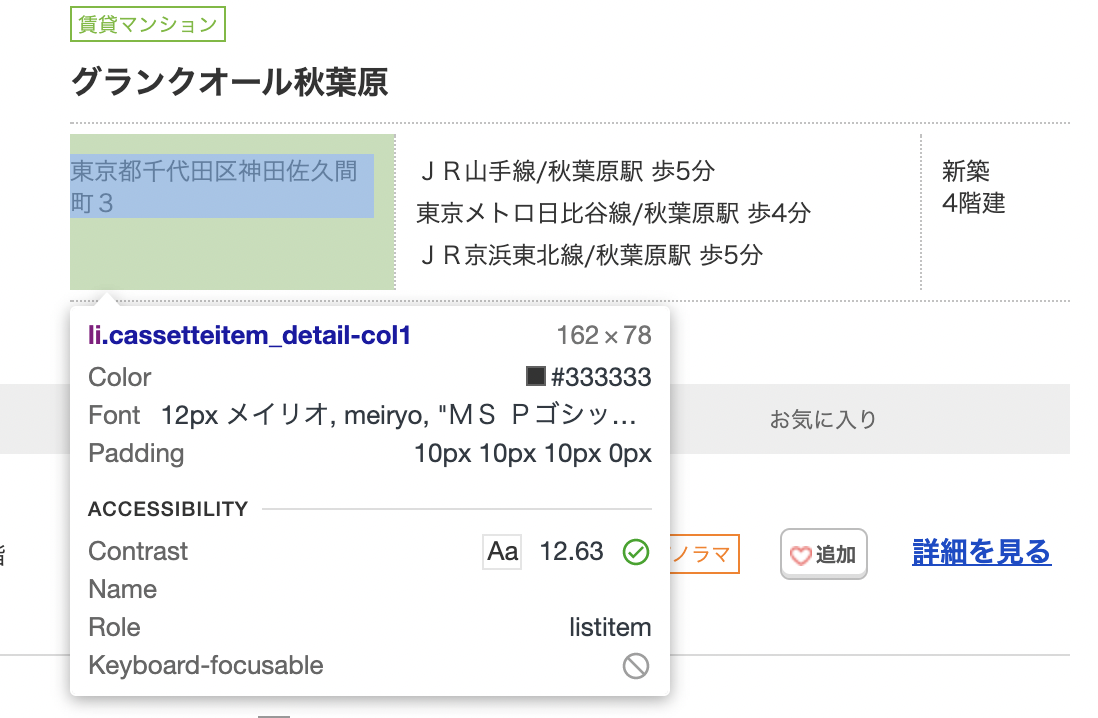
建物単位のスクレイピング - 住所
EstateAddress = EstateElem.find("li",{'class':'cassetteitem_detail-col1'}).get_text()
最寄り駅
最寄り駅は3つで区切られているので、あとから処理しやすいように「---」を入れて1つの要素として格納します。
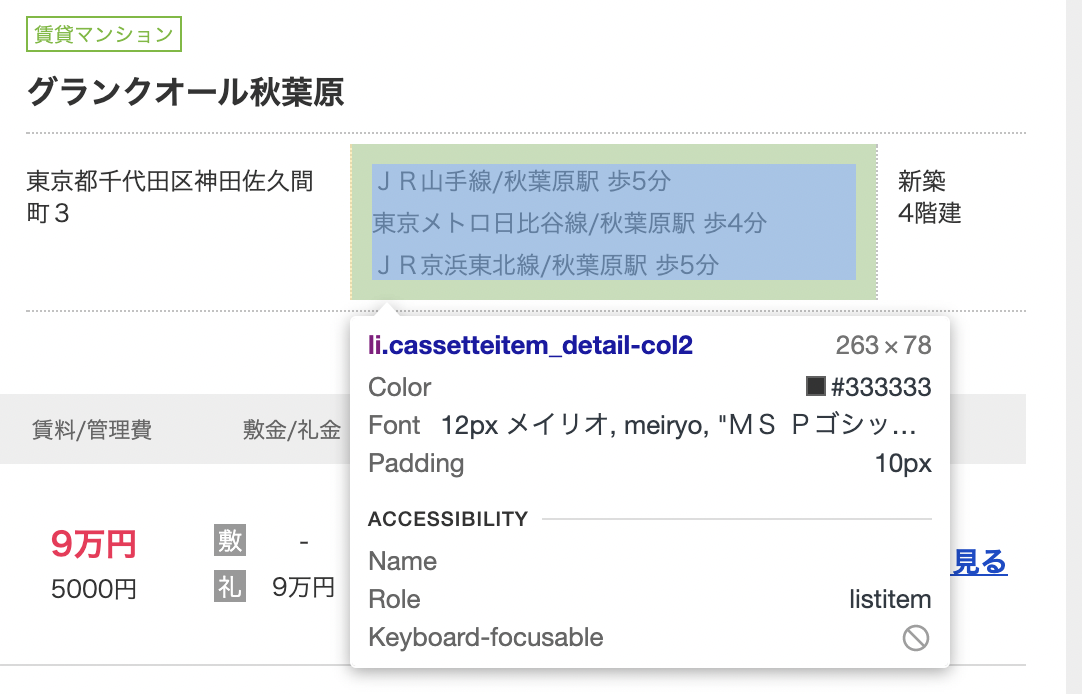
建物単位のスクレイピング - 最寄り駅
EstateLocationElem = EstateElem.find("li",{'class':'cassetteitem_detail-col2'}).find_all("div",{'class':'cassetteitem_detail-text'})
EstateLocations = [EstateLocation.get_text() for EstateLocation in EstateLocationElem]
EstateLocation = ' --- '.join(EstateLocations)
築年数と建物高さ
築年数と建物高さは、確実に2つだったので、[0]と[1]でハードコードしています。
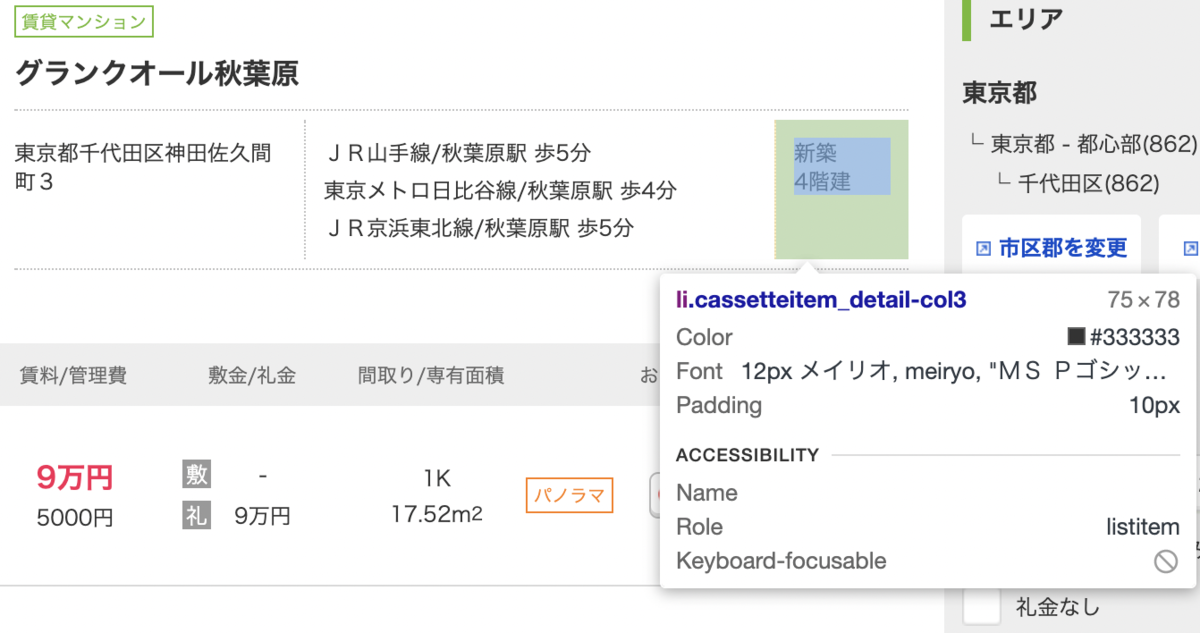
建物単位のスクレイピング - 築年数と建物高さ
EstateCol3Elem = EstateElem.find("li",{'class':'cassetteitem_detail-col3'}).find_all("div")
EstageAge = EstateCol3Elem[0].get_text()
EstageHight = EstateCol3Elem[1].get_text()
データの格納
最後に結果をリストに格納します。また、どの検索ページだったのかを記録するために最後に検索ページURLを格納しています。
HeaderInfo = [EstateName, EstateAddress, EstateLocation, EstageAge, EstageHight, url]
Step2 - 部屋情報のTable要素を抜き出す
次に部屋単位の情報をスクレイピングしていきます。その前準備として、部屋情報の記載があるTableのHTML要素を抜き出します。
RoomtableElem = EstateElem.find("table",{'class':'cassetteitem_other'})
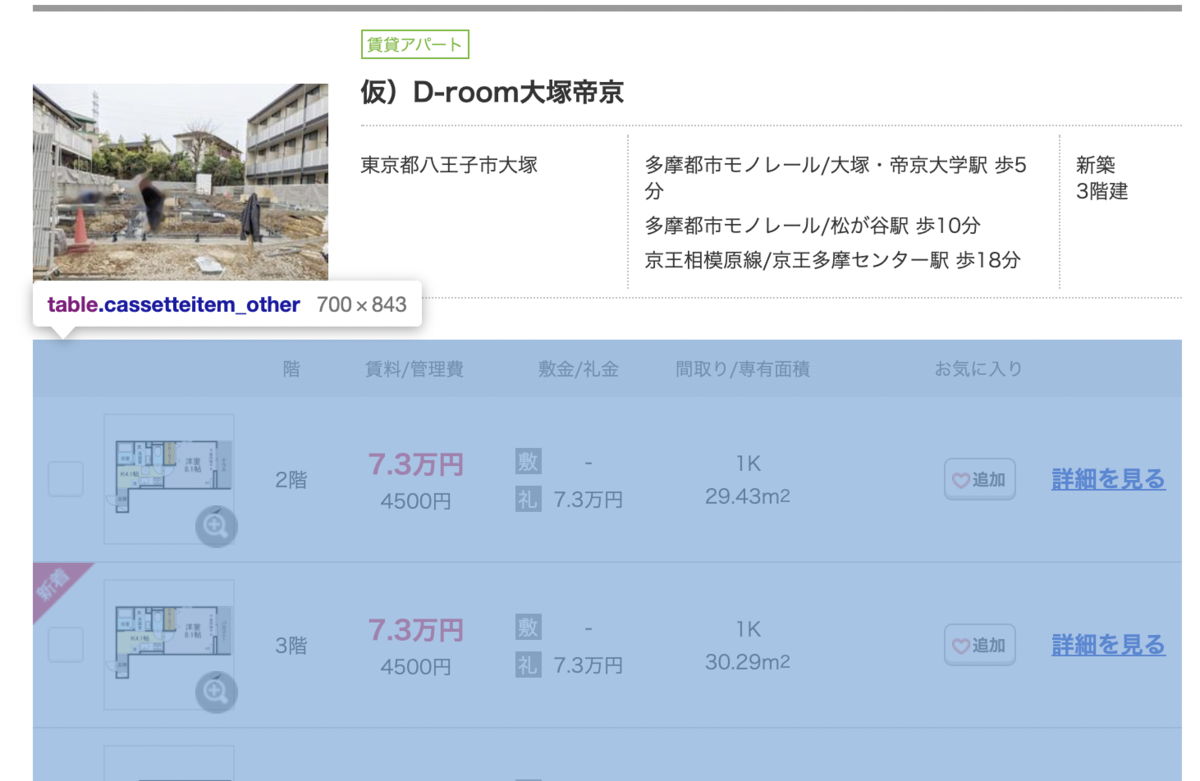
Step2 - 部屋情報のTable要素を抜き出す
Step3 - 部屋単位の情報をスクレイピング
部屋ごとの情報を抜き出します。1つの建物で複数空き部屋がある場合は、部屋の数だけループが回ることになります。
テーブルのテキスト情報は一括で抜き出してしまいます。
RoomDetail = []
for rooms in RoomtableElem.find_all("tbody"):
Roomtable = [temp.get_text() for temp in rooms.findAll('td')]
Step3.1 - 新着かどうか
新着かどうかは、画像のクラスを見ると判断できます。
if "cassetteitem_other-checkbox--newarrival" in rooms.td['class']:
Roomtable.append("New")
else:
Roomtable.append("Exsiting")
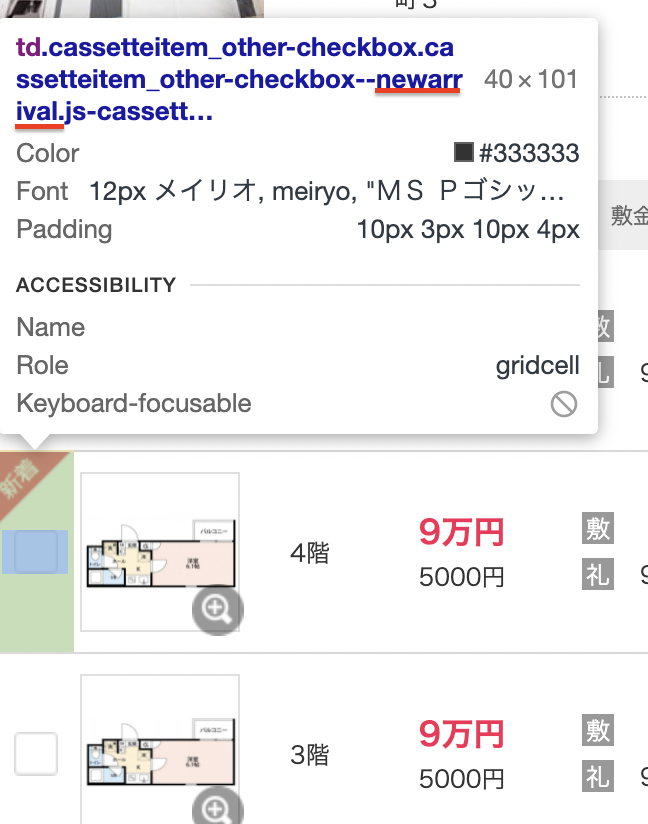
新着の場合
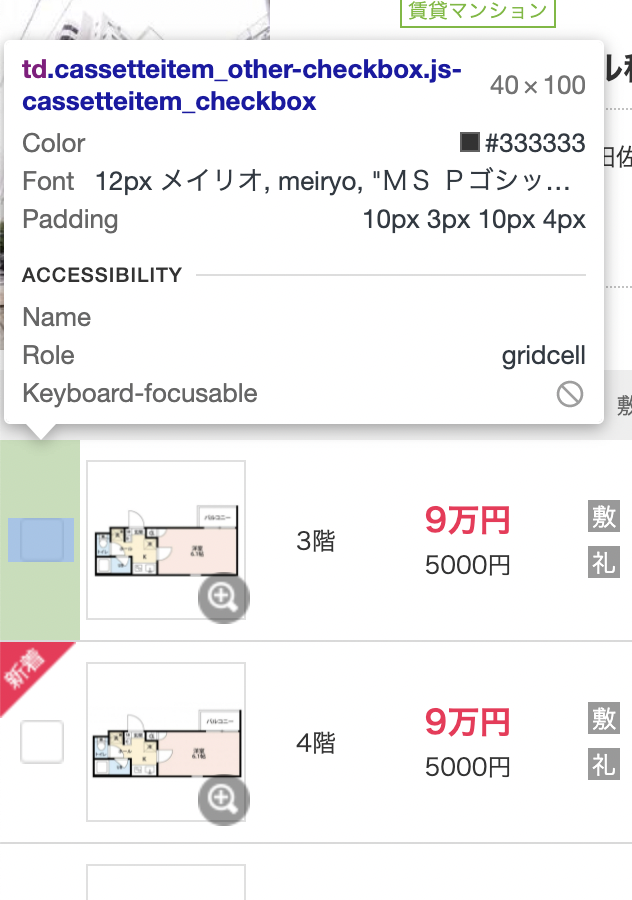
既存物件の場合
Step3.2 - 部屋の詳細リンクを取得する
部屋の詳細リンクは下記のようにhrefを取ってくれば取得できます。このリンクは相対URLになっているので、あとから面倒にならないように絶対URLに変換してあげます。
Roomlinks = EstateElem.select("a[href]")
RoomDetailURL = [link.get("href") for link in Roomlinks if link.get_text() == "詳細を見る"][0]
RoomFullDetailURL = urljoin("https://suumo.jp/", RoomDetailURL)
Roomtable.append(RoomFullDetailURL)
最後に解説したソースコードを載せておきます。(GitHubにありますけどね) github.com
from bs4 import BeautifulSoup
import requests
import pandas as pd
import time
from urllib.parse import urljoin
def PageNum_Easy(url):
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c, "html.parser")
body = soup.find("body")
pages = body.find("div",{'class':'pagination pagination_set-nav'})
links = pages.select("a[href]")
nPages = [int(link.get_text()) for link in links if link.get_text().isdigit()]
if len(nPages) == 0:
PageFullURLs = [url]
else:
MaxPages = sorted(nPages)[-1]
PageFullURLs = []
for ipg in range(MaxPages):
base_URL = url + '&page=' + str(ipg+1)
PageFullURLs.append(base_URL)
return PageFullURLs
def ParseRoomDetail(EstateElem, url):
EstateName = EstateElem.find("div",{'class':'cassetteitem_content-title'}).get_text()
EstateAddress = EstateElem.find("li",{'class':'cassetteitem_detail-col1'}).get_text()
EstateLocationElem = EstateElem.find("li",{'class':'cassetteitem_detail-col2'}).find_all("div",{'class':'cassetteitem_detail-text'})
EstateLocations = [EstateLocation.get_text() for EstateLocation in EstateLocationElem]
EstateLocation = ' --- '.join(EstateLocations)
EstateCol3Elem = EstateElem.find("li",{'class':'cassetteitem_detail-col3'}).find_all("div")
EstageAge = EstateCol3Elem[0].get_text()
EstageHight = EstateCol3Elem[1].get_text()
HeaderInfo = [EstateName, EstateAddress, EstateLocation, EstageAge, EstageHight, url]
RoomtableElem = EstateElem.find("table",{'class':'cassetteitem_other'})
RoomDetail = []
for rooms in RoomtableElem.find_all("tbody"):
Roomtable = [temp.get_text() for temp in rooms.findAll('td')]
if "cassetteitem_other-checkbox--newarrival" in rooms.td['class']:
Roomtable.append("New")
else:
Roomtable.append("Exsiting")
Roomlinks = EstateElem.select("a[href]")
RoomDetailURL = [link.get("href") for link in Roomlinks if link.get_text() == "詳細を見る"][0]
RoomFullDetailURL = urljoin("https://suumo.jp/", RoomDetailURL)
Roomtable.append(RoomFullDetailURL)
Roomtable.extend(HeaderInfo)
RoomDetail.append(Roomtable)
return RoomDetail
def Parsedistrict(PageFullURLs, RoomDetails):
for icount, url in enumerate(PageFullURLs):
print(" Room Detail Status: " + str(icount + 1) + "/" + str(len(PageFullURLs)))
try:
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c, "html.parser")
summary = soup.find("div",{'id':'js-bukkenList'})
cassetteitems = summary.find_all("div",{'class':'cassetteitem'})
for EstateElem in cassetteitems:
RoomDetails.extend(ParseRoomDetail(EstateElem, url))
except requests.exceptions.RequestException as e:
print("エラー : ",e)
time.sleep(5)
print("total # of Rooms: " + str(len(RoomDetails)))
return RoomDetails
BaseURLs = [
"https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=13",
"https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=14",
"https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=12",
"https://suumo.jp/jj/chintai/ichiran/FR301FC001/?url=%2Fchintai%2Fichiran%2FFR301FC001%2F&ar=030&bs=040&pc=30&smk=&po1=25&po2=99&co=1&kz=1&kz=2&kz=4&tc=0400101&tc=0400501&tc=0400301&shkr1=03&shkr2=03&shkr3=03&shkr4=03&cb=0.0&ct=12.0&et=15&mb=0&mt=9999999&cn=15&ta=11"
]
soup = BeautifulSoup(requests.get(BaseURLs[0]).content, "html.parser")
body = soup.find("body")
RoomtableHeadElem = body.find("div",{'class':'cassetteitem'}).find("thead").find_all("th")
HeaderNames = [temp.get_text() for temp in RoomtableHeadElem]
HeaderNames.append("NewArrival")
HeaderNames.append("RoomDetailLink")
HeaderNames.extend(["マンション名", "住所", "最寄り駅", "築年数", "建物高さ","SearchURL"])
HeaderNames = [temp.replace("\xa0", str(i)) for i, temp in enumerate(HeaderNames)]
for iMcount, url in enumerate(BaseURLs):
print("District Status: " + str(iMcount + 1) + "/" + str(len(BaseURLs)))
All_PageFullURLs = []
All_PageFullURLs = PageNum_Easy(url)
RoomDetails = []
RoomDetails = Parsedistrict(All_PageFullURLs, RoomDetails)
df = pd.DataFrame(RoomDetails, columns = HeaderNames)
filename = "SUMMO_FullRoom_" + str(iMcount) + ".csv"
df.to_csv(filename)
おわりに
お疲れ様でした。物件データって身近なビックデータなので解析しよう!!っていう気になりますよね。それが自分の住む場所を決めるかもしれないですし。ぜひご自身の物件探しや研究活動に使用いただければと思います。
普段私のブログではKNIMEというETLノーコードツールをメインに紹介しています。もし興味があればぜひ遊びにきてください。Twitterもやっているのでぜひフォローいただければと思います。ではまた!
twitter.com
degitalization.hatenablog.jp
参考リンク