
はじめに
こんにちは、まっきーです。今回は「XML構造を簡単に分解するNode」を解説したいと思います。簡単なXMLファイルの例として、本ブログのサイトマップを使用したいと思います。
XML例 サイトマップ:https://degitalization.hatenablog.jp/sitemap.xml
今回のテーマ ~XPath~
前回開設したGET RequestのNodeと一緒に使うことが多いです。

覚えてほしいこと
やりたいこと - XPath
今回は本ブログのサイトマップ「https://degitalization.hatenablog.jp/sitemap.xml」のXMLをKNIMEで分解してみたいと思います。

はてなブログには、必ずサイトマップというwebページの目次のようなものがついています。好きなブログのURLに「/sitemap.xml」という末尾をつけてみてください。サイトマップがXMLの形式で見れると思います。
XMLとは?
先ほどから出てきているXMLとは、JSONと同じようなもので、下記のようなタグで囲まれた構造をした文章・データです。
こんな構造のデータなんだなーくらいの意識で問題ないです。
今回のサイトマップを実際に見てみると、なんとなく分かると思います。
タグとは<sitemap>, <loc>, <lastmod>の部分を言います。データがタグで囲われてますよね。

事前準備 - GET RequestでサイトマップをXMLで取得
事前準備として、GET RequestでXML形式のデータをKNIMEに取り込みましょう。Configureだけ載せます。

XPathの使い方
このNodeはXML構造のデータを簡単に分解するNodeです。GET RequestでXML形式のデータを読み込んだ後によく出てきます。
Workflow - XPath

Workflowは下記からダウンロードできます。
Confirm - XPath
XPathを実行後、XML構造で1行しかなかったデータが、繰り返し構造を利用して複数行に分けられていることがわかると思います。
Configure - Xpath
色々設定があるように見えますが、XPath summaryの部分のみ重要です。
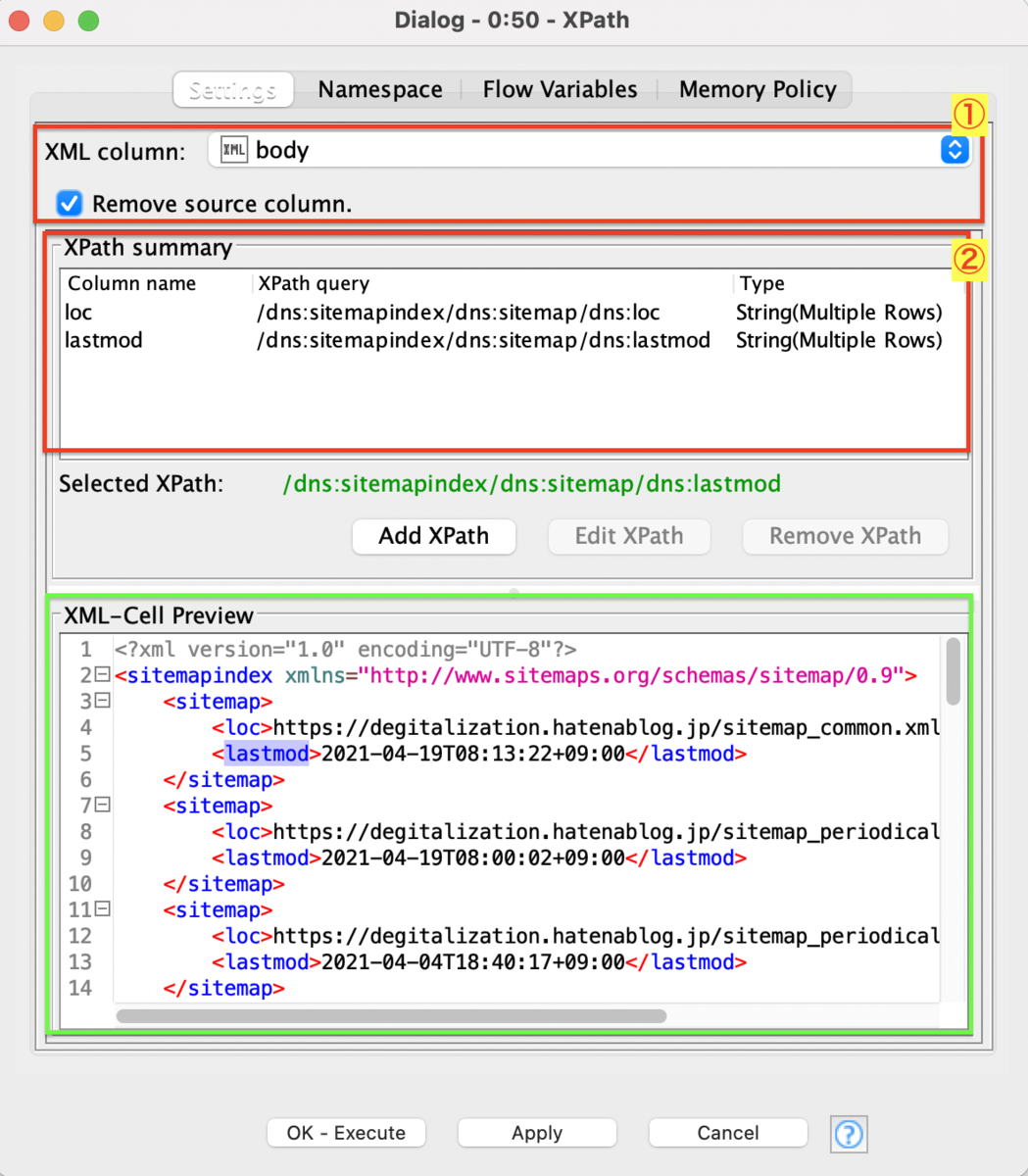
Step1 - XML Column - 対象のXMLコラムを指定
まずはXMLのコラムを指定します。
また、残っていると結果が見づらくなるので、Remove source columnにはチェックを入れておくことをオススメします。
Step2 - XPath Summary - 抽出ルール指定
XML構造は規則性があるので、そのタグの階層を指定してあげることによって同じ階層の同じタグのデータを抜き出してくるというのがこのNodeでできることです。
そういうと、難しく聞こえるかもしれませんが、難しい部分はKNIMEがやってくれるので、安心してください。
XPath Summaryの部分では現在定義している抽出ルールを一覧でみることができます。
XPath Summaryのルール一覧は下記の3つのボタンで編集できます。
抽出ルールの定義の仕方 - Add XPath と XML-Cell Preview
ここが1番重要です。下記の3ステップで抽出ルールを指定できます。
まずは1、2の部分です。XML-Cell Preview上で抽出したいデータの部分をクリックします。すると、KNIME側が階層を勝手に認識してくれます。(Selected XPathの部分)
あとは、「Add XPath」を押せばOKです。

Add XPathをクリックすると、下図のポップアップが出てきます。ここで抽出方法の詳細を定義します。

とはいえ、ほとんど設定はデフォルトで問題なく、唯一最後のMultiple tag optionsだけ指定してあげましょう。
- Column Name:抽出後のコラム名を指定。データに応じてコラム名を変えるかを指定できます。
- Retrun Type:抽出後のデータ型を指定できます。まずはStringで取り込み、後から変換でいいともいます。
- Multiple tag options:データのOutputをどのように出力するかを選択します。これが重要です。
今回は、複数行でデータを取得したいので、Multiple tag optionsにMultiple Rowsを指定すればOKです。
ちょっと一言
Multiple tag optionsの種類について
どのようなOutputの形式で出てくるのか、いまいち分からないと思うのでここで実際のOutputを見て理解していきましょう。
- Single Cell - 指定されたXPathの値のみを単体のCellで返す。(規則性で複数返すことはしない)

- Collection Cell - Collection型でデータを格納する

Collection型は以前UngroupのNodeの時に扱いましたね。
- Multiple Columns - 複数コラムとして出力

- Multiple Rows - 複数行として出力

おわりに
お疲れ様でした!XPathは1回やってみたら簡単にコツを掴めるNodeだと思います。ぜひ一度試してみてください。
また、今回分解して取得したXMLのURLをもう一度GET Requestをしてみるとどうなるか、ぜひ試してみてください。
「https://degitalization.hatenablog.jp/sitemap_periodical.xml?year=2021&month=1」
これを使えば、ブログの情報一覧が自動で取得できるようになりますよ!ではまた!
余談
もうすぐゴールデンウィークですね!予定は決まっていますか?
昨年はブログばかり書いていましたが、今回は少しお休みして、ソロキャンでもしようと思っています。道具を集めて出費が大変なことになっていますが。自然を見てボーッとしたいですね。適度に息抜きしてコロナともうまく付き合いたいものです。
ではまた!
KNIMEに関する本
KNIMEに関する日本語の本って今これくらいしかないと思うんですよね、、
本がいいなーと言う人はぜひ試してみてください。

参考リンク
- すさんのブログ:
KNIMEで明日の天気を調べよう! 〜REST APIの活用〜 - 非プログラマーのためのインフォマティクス入門。(仮)
- KNIME公式Node Pit(英語):
- KNIME Example Workflow(英語):