
はじめに
こんにちは、自動化大好きまっきーです。今回は久しぶりのPythonについてです。
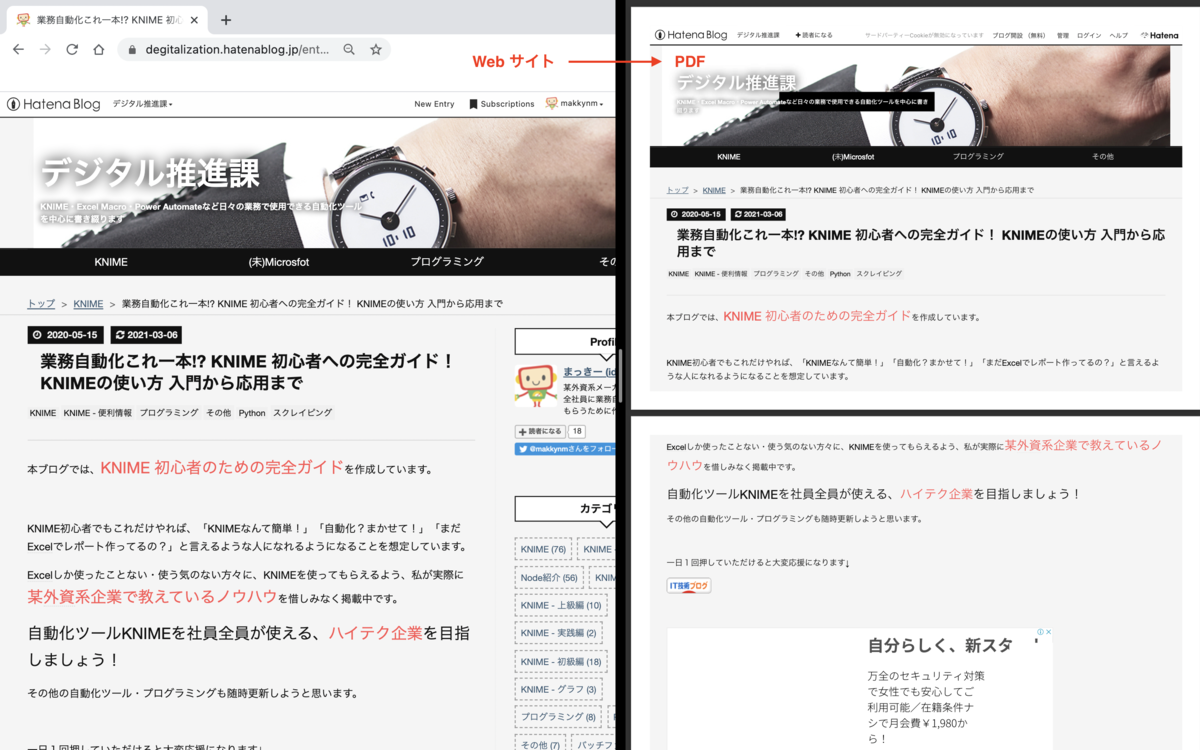
みなさん、WebページをPDFで保存するとき、いちいち印刷ボタンを押してPDFで保存するという面倒なことやっていませんか?
私はこの方法しか知りませんでした。しかし、大量のWebページについてPDF保存しないといけない場合どうしましょうか。いちいちそのURLに行ってPDF保存って面倒ですよね。そこでPythonでWebページを一括保存するやり方をご紹介したいと思います。
htmlからPDFへの自動変換としても使える方法だと思います。
使い方は色々です。Webシステムにある電子書類のPCへの自動保存にも使えるかもしれませんね。
Selenium以外にもPDF変換できるパッケージがあったようですが、あまり色々パッケージを入れたくないのと、ログインのあるWebサイトにも対応できるようにSeleniumでコーディングしました。
今回のテーマ ~Web Page to PDF~
Codeはこちらから。
覚えてほしいこと - Selenium print option
WebページをPDFで自動保存するには印刷オプションを指定してSeleniumで実行
やりたいこと - Web Page もしくはhtmlをPDFに自動変換
まずは本ブログのまとめページである、下記のページをPDF変換していきたいと思います。
https://degitalization.hatenablog.jp/entry/2020/05/15/084033
同じ方法で、htmlの印刷も行います。
繰り返し文を使用して、複数Webサイト・htmlをPDFに一括変換するコードを作っていきたいと思います。
きっかけ - 無料ブログのデメリットへのリスクヘッジ - Webページの自動バックアップ
私は本ブログの各ページを、PDF保存したいと考えています。なぜなら、せっかく大量の時間をかけて書いたデータがネット上にしかないのがリスクだと思うからです。
よくブロガー界隈で言われていると思います。
「無料ブログは突然サービスが終了したり、運営側の意図でいきなり消されることがある。だから月2000円くらいかけて有料のWordPressにしたほうがいい。」と。
でも私のような社員に見てもらうために作ったブログの場合、わざわざ月2000円出すの嫌じゃないですか、、収益もないし、わざわざ勤務時間外に書いた記事のために(すみませんケチで。。。)
そこで、Webページの自動バックアップシステムをPythonで作ろうと思います。この記事はその第一弾になります。
使用環境
Pythonの実行環境があれば基本実行できるはずです。私は下記の環境を使用しました。
- Apple MacBook Air M1 搭載モデル
- Python 3.9.1
- Selenium 3.141.0
 - スペースグレイ")
最新 Apple MacBook Air Apple M1 Chip (13インチPro, 8GB RAM, 256GB SSD) - スペースグレイ
- 発売日: 2020/11/17
- メディア: Personal Computers
全体フロー
全体のフローはこんな感じです。
- 必要モジュールのImport
- 関数の定義 - 印刷オプションの設定
- 関数の定義 - スクレイピングの実行
- URLの指定・関数の呼び出し
Step1 - 必要モジュールのImport
今回使うのは下記のモジュールです。
印刷オプションの設定用にjson
ポーズ用にtime
という形です。
Step2 - 印刷オプションの設定 - Chrome Driver Print Option
続いて印刷オプションの設定になります。いろんなサイト見たんですが、最低限の印刷オプションしか解説されていなかったので少し困ったんですよね。
人それぞれやりたいことが違うと思うので、コメントアウトで今回使わなかったオプションを掲載しています。
こちらは関数化していて、この関数は最終的に、”chopt”というオプションの設定が格納された変数を返しています。下記のコードから分かるとは思いますが、
appState --> prefs --> chopt
と言う形で変数が移り変わっています。
Step2.1 -appStateの定義
ここが肝と言ってもいいかもしれません。これは、Chromeで印刷するときに出てくる設定を定義している部分になります。全部は使わないと思いますが、各オプションについて解説します。
私が調べた限りの範囲なので、こんなのもあるよ、これ間違っているよと言うのがあればぜひコメントいただければと思います。

app Stateの定義 - 印刷オプションの定義
コメントアウトで解説つけているので分かると思いますが、箇条書きで載っけておきます。
- "recentDestinations"/"selectedDestinationId"/"version":PDF保存を指定
- "isLandscapeEnabled":印刷の向きを指定 tureで横向き、falseで縦向き。
- "pageSize":用紙タイプ(A3、A4、A5、Legal、 Letter、Tabloidなど)
- "mediaSize": 紙のサイズ (10000マイクロメートル = 1cm)
- "scalingType":0:デフォルト 1:ページに合わせる 2:用紙に合わせる 3:カスタム
- "scaling":倍率
- "isHeaderFooterEnabled": ヘッダーとフッター
- "isCssBackgroundEnabled":背景のグラフィック
- "isDuplexEnabled":両面印刷 tureで両面印刷、falseで片面印刷
- "isCollateEnabled":部単位で印刷
- "profile.managed_default_content_settings.images":画像を読み込ませない
Step2.2 -prefの定義 - appStateを引数に格納する
やっていることは単純です。appStateで定義した内容をprinting.print_preview_sticky_settings.appStateと言う引数格納するために、形式を変換している部分になります。
また、下記の引数で保存先も指定しています。
- "download.default_directory":保存先の指定(WindowsだとC:\\Users\\downloadなど)
Step2.3 -chopt の定義 - Chromeのオプションとして格納
行っているコードは下記の3つですね。Chromeの設定として先ほどの印刷オプションを格納します。
- chopt=webdriver.ChromeOptions():Chromeのオプションとして定義
- chopt.add_experimental_option('prefs', prefs):印刷オプションを格納
- chopt.add_argument('--kiosk-printing') :印刷ダイアログが開くと、印刷ボタンを無条件に押す
Step3 - Selenium スクレイピングの実行
続いてスクレイピングの実行関数です。スクレイピングといっても、ブログのURLにアクセスして、印刷ボタン押してるだけですけどね。
引数はURLになります。htmlの場合はファイルパスです。
Step 3.1 WebDriverの定義
まずはChrome Driverのパスを入れてパスを定義します。また、先ほど関数で定義した印刷オプションも、関数を実行して変数として格納します。
下記のコードで、ドライバを印刷オプションを適用した状態で定義しています。
driver = webdriver.Chrome(executable_path=driver_path, options=chopt)
Step 3.2 待機処理について
待機処理として3種類入れています。
- driver.implicitly_wait(10):10秒の暗示的待機です。待機時間のデフォルト設定みたいな感じですね。
- WebDriverWait(driver, 15).until(EC.presence_of_all_elements_located):ページの要素が読み込まれるまで待ちます。最大15秒です。
- time.sleep(10) :10秒待ちます。ファイルのダウンロードに要する時間の待機です。ダウンロードが完了する前に画面を閉じてしまうとダウンロードできないので。
Step 3.3 PDF印刷実行
driver.execute_script('return window.print()') :この部分でPDF印刷の実行を行います。今までの積み上げてきた設定をここで一気に実行している感じですね。
PDFの保存名はTitleタグから取ってきているようです。
Step4 - 関数の呼び出し
ここで、Step2, Step3で定義した関数を呼び出します。
BlogURLListをList型で定義しています。ここにPDF化したいURLを入力します。
htmlファイルを変換したい場合は、「file://」からファイルパスを入力します。
コード
さて、今までのコードを総括すると、こうなります。
おわりに
お疲れ様でした!Driverオプション、種類が多すぎて調べても全オプション全然出てこずに見つけるのかなり苦労しましたね。皆さんの役に立てれば幸いです!
KNIMEに関する記事が主ですが、たまにPythonについても書くのでよかったら応援お願いします!
一日1回押していただけると大変応援になります↓
![]()
Mac M1など、USB Cを使える方へのおすすめをあげておきます。
おすすめTypeC変換器: 7 in 1
私はこちらを購入しました。HDMIとVGAがついているので、拡張画面や発表するときには安心ですよね。また、USBポートはもちろん、TypeC、SDカードも含まれているので、これさえあれば最低限カバーできるはずです!

TypeC変換器 その2: 11 in 1
有線のLANケーブルのポートも欲しいという方はこちらをお勧めします。また、USBポートが3つついていることも魅力ですね。
先ほどあげた、SDカード・HDMI・VGA・TypeCも含まれているので、これさえあれば充分ですね!

USB TypeC 対応Display

LG モニター ディスプレイ 27UL850-W 27インチ/4K/DisplayHDR400/IPS非光沢/USB Type-C、DP、HDMI×2/スピーカー/FreeSync/高さ調節、ピボット
- 発売日: 2018/12/13
- メディア: Personal Computers

- メディア: エレクトロニクス